本文通过代码驱动的方式,系统讲解PyTorch核心概念和实战技巧,涵盖张量操作、自动微分、数据加载、模型构建和训练全流程,并实现线性回归与多层感知机模型。
import torch
# 创建张量
scalar = torch.tensor(3.14) # 标量(0维)
vector = torch.tensor([1, 2, 3]) # 向量(1维)
matrix = torch.tensor([[1, 2], [3, 4]]) # 矩阵(2维)
tensor_3d = torch.randn(2, 3, 4) # 随机3维张量
print(f"标量: {scalar}\n形状: {scalar.shape}")
print(f"3D张量:\n{tensor_3d}\n形状: {tensor_3d.shape}")
# 基础运算
a = torch.tensor([1, 2, 3])
b = torch.tensor([4, 5, 6])
print("加法:", a + b) # 逐元素加法
print("乘法:", a * b) # 逐元素乘法
print("点积:", torch.dot(a, b)) # 向量点积
print("矩阵乘法:", matrix @ matrix.T) # 矩阵乘法
# 形状变换
original = torch.arange(12)
reshaped = original.view(3, 4) # 视图(不复制数据)
cloned = original.reshape(3, 4) # 新内存副本
print("原始张量:", original)
print("视图重塑:\n", reshaped)# 索引操作
tensor = torch.tensor([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
print("第一行:", tensor[0]) # [1,2,3]
print("最后一列:", tensor[:, -1]) # [3,6,9]
print("子矩阵:\n", tensor[1:, :2]) # [[4,5],[7,8]]
# 广播机制
A = torch.tensor([[1, 2], [3, 4]])
B = torch.tensor([10, 20])
# B被广播为[[10,20],[10,20]]
print("广播加法:\n", A + B)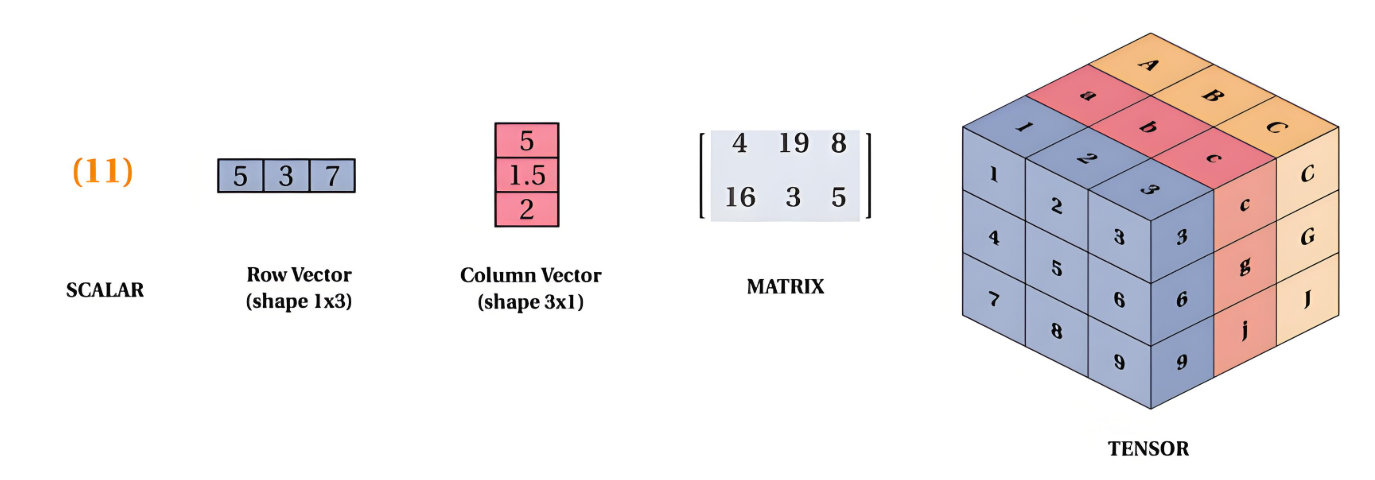
# 创建需要梯度的张量
x = torch.tensor(2.0, requires_grad=True)
y = torch.tensor(3.0, requires_grad=True)
# 定义计算图
z = x**2 + y**3 + 10
# 反向传播计算梯度
z.backward()
print(f"dz/dx = {x.grad}") # 2x = 4
print(f"dz/dy = {y.grad}") # 3y² = 27# 多步骤计算
a = torch.tensor([1.0, 2.0], requires_grad=True)
b = torch.tensor([3.0, 4.0], requires_grad=True)
c = a * b # [3, 8]
d = c.sum() * 2 # (3+8)*2=22
d.backward()
print("a的梯度:", a.grad) # [6, 8]
print("b的梯度:", b.grad) # [2, 4]x = torch.tensor(5.0, requires_grad=True)
# 第一次计算
y1 = x**2
y1.backward()
print("第一次梯度:", x.grad) # 2x=10
# 第二次计算(梯度累积)
y2 = x**3
y2.backward()
print("累积梯度:", x.grad) # 10 + 3x²=10+75=85
# 梯度清零
x.grad.zero_()
y3 = 2*x
y3.backward()
print("清零后梯度:", x.grad) # 2from torch.utils.data import Dataset, DataLoader
import numpy as np
class CustomDataset(Dataset):
def __init__(self, data_size=100):
self.X = np.random.rand(data_size, 3) # 3个特征
self.y = self.X[:,0]*2 + self.X[:,1]*3 - self.X[:,2]*1.5
def __len__(self):
return len(self.X)
def __getitem__(self, idx):
features = torch.tensor(self.X[idx], dtype=torch.float32)
target = torch.tensor(self.y[idx], dtype=torch.float32)
return features, target
# 实例化数据集
dataset = CustomDataset(1000)
# 可视化数据分布
import matplotlib.pyplot as plt
plt.figure(figsize=(12,4))
plt.subplot(131)
plt.scatter(dataset.X[:,0], dataset.y)
plt.title('特征1 vs 目标值')
plt.subplot(132)
plt.scatter(dataset.X[:,1], dataset.y)
plt.title('特征2 vs 目标值')
plt.subplot(133)
plt.scatter(dataset.X[:,2], dataset.y)
plt.title('特征3 vs 目标值')
plt.tight_layout()
plt.show()# 创建数据加载器
dataloader = DataLoader(
dataset,
batch_size=32,
shuffle=True,
num_workers=2
)
# 迭代获取批次数据
for batch_idx, (inputs, targets) in enumerate(dataloader):
print(f"批次 {batch_idx}:")
print(f"输入形状: {inputs.shape}")
print(f"目标形状: {targets.shape}")
# 仅展示前两个批次
if batch_idx == 1:
breakimport torch.nn as nn
class LinearRegression(nn.Module):
def __init__(self, input_dim):
super().__init__()
self.linear = nn.Linear(input_dim, 1)
def forward(self, x):
return self.linear(x)
# 实例化模型
model = LinearRegression(input_dim=3)
print("模型结构:\n", model)
# 查看模型参数
for name, param in model.named_parameters():
print(f"{name}: {param.shape}")class MLP(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super().__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
x = self.fc2(x)
return x
# 创建MLP模型
mlp = MLP(input_size=3, hidden_size=16, output_size=1)
print("MLP结构:\n", mlp)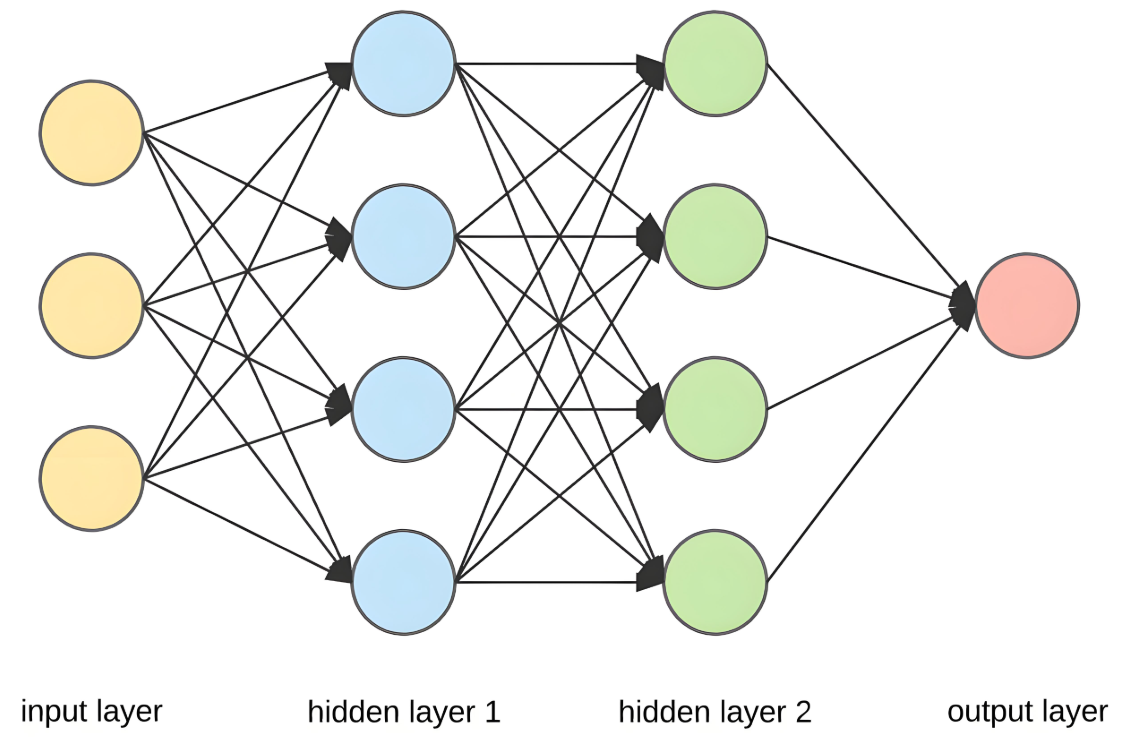
# 配置训练参数
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = LinearRegression(3).to(device)
criterion = nn.MSELoss() # 均方误差损失
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# 训练循环
num_epochs = 100
loss_history = []
for epoch in range(num_epochs):
epoch_loss = 0
# 批次训练
for inputs, targets in dataloader:
inputs, targets = inputs.to(device), targets.to(device)
# 前向传播
outputs = model(inputs)
loss = criterion(outputs, targets.unsqueeze(1))
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_loss += loss.item()
# 记录平均损失
avg_loss = epoch_loss / len(dataloader)
loss_history.append(avg_loss)
# 每10轮打印损失
if (epoch+1) % 10 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {avg_loss:.4f}')
# 绘制损失曲线
plt.plot(loss_history)
plt.title('训练损失变化')
plt.xlabel('Epochs')
plt.ylabel('MSE Loss')
plt.grid(True)
plt.show()# 切换到评估模式
model.eval()
# 禁用梯度计算
with torch.no_grad():
test_inputs = torch.tensor(dataset.X, dtype=torch.float32)
predictions = model(test_inputs)
actuals = torch.tensor(dataset.y, dtype=torch.float32).unsqueeze(1)
# 计算评估指标
mse = criterion(predictions, actuals)
mae = torch.mean(torch.abs(predictions - actuals))
print(f'测试集MSE: {mse.item():.4f}')
print(f'测试集MAE: {mae.item():.4f}')
# 可视化预测结果
plt.scatter(actuals, predictions, alpha=0.6)
plt.plot([actuals.min(), actuals.max()],
[actuals.min(), actuals.max()], 'r--')
plt.title('预测值 vs 真实值')
plt.xlabel('真实值')
plt.ylabel('预测值')
plt.grid(True)
plt.show()# 生成合成数据
X = torch.linspace(0, 10, 100).reshape(-1, 1)
y = 3 * X + 2 + torch.randn(100, 1) * 2
# 定义模型
class LinearReg(nn.Module):
def __init__(self):
super().__init__()
self.linear = nn.Linear(1, 1)
def forward(self, x):
return self.linear(x)
# 训练配置
model = LinearReg()
optimizer = torch.optim.Adam(model.parameters(), lr=0.1)
criterion = nn.MSELoss()
# 训练循环
for epoch in range(200):
# 前向传播
preds = model(X)
loss = criterion(preds, y)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 可视化训练过程
if epoch % 50 == 0:
plt.scatter(X, y, label='原始数据')
plt.plot(X, preds.detach().numpy(), 'r-', lw=3, label='模型预测')
plt.title(f'Epoch {epoch}, Loss: {loss.item():.4f}')
plt.legend()
plt.show()
plt.pause(0.1)
plt.clf()
# 输出学习到的参数
print("权重:", model.linear.weight.item())
print("偏置:", model.linear.bias.item())from torchvision import datasets, transforms
# 数据预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
# 加载MNIST数据集
train_data = datasets.MNIST('./data', train=True, download=True, transform=transform)
test_data = datasets.MNIST('./data', train=False, transform=transform)
# 创建数据加载器
train_loader = DataLoader(train_data, batch_size=64, shuffle=True)
test_loader = DataLoader(test_data, batch_size=1000)
# 定义MLP模型
class MLPClassifier(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(28*28, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, 10)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(0.2)
def forward(self, x):
x = x.view(-1, 28*28) # 展平
x = self.relu(self.fc1(x))
x = self.dropout(x)
x = self.relu(self.fc2(x))
x = self.fc3(x)
return x
# 训练函数
def train(model, device, train_loader, optimizer, criterion, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print(f'Train Epoch: {epoch} [{batch_idx*len(data)}/{len(train_loader.dataset)}'
f' ({100.*batch_idx/len(train_loader):.0f}%)]\tLoss: {loss.item():.6f}')
# 测试函数
def test(model, device, test_loader, criterion):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += criterion(output, target).item()
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
accuracy = 100. * correct / len(test_loader.dataset)
print(f'\n测试集: 平均损失: {test_loss:.4f}, 准确率: {correct}/{len(test_loader.dataset)} ({accuracy:.2f}%)\n')
return accuracy
# 主训练循环
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = MLPClassifier().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
accuracy_history = []
for epoch in range(1, 11):
train(model, device, train_loader, optimizer, criterion, epoch)
acc = test(model, device, test_loader, criterion)
accuracy_history.append(acc)
# 绘制准确率曲线
plt.plot(accuracy_history)
plt.title('MNIST分类准确率')
plt.xlabel('Epochs')
plt.ylabel('Accuracy (%)')
plt.grid(True)
plt.show()
graph TD A[创建张量] --> B[基础运算] B --> C[形状变换] C --> D[索引切片] D --> E[广播机制]
自动求导三步骤:
# 1. 设置requires_grad=True x = torch.tensor(2.0, requires_grad=True) # 2. 前向计算 y = x**2 + 3*x + 1 # 3. 反向传播 y.backward() print(x.grad) # 导数: 2x+3 = 7
数据加载最佳实践:
自定义Dataset类实现__len__和__getitem__
使用DataLoader进行批次加载和混洗
多进程加速设置num_workers>0
模型构建模式:
class CustomModel(nn.Module): def __init__(self): super().__init__() # 定义网络层 def forward(self, x): # 定义数据流向 return output
训练循环模板:
for epoch in range(epochs): for data in dataloader: inputs, labels = data # 前向传播 outputs = model(inputs) loss = criterion(outputs, labels) # 反向传播 optimizer.zero_grad() loss.backward() optimizer.step()
调试技巧:
使用torch.sum()检查张量值
print(model)查看网络结构
torch.autograd.set_detect_anomaly(True)检测梯度异常
更多AI大模型应用开发学习视频内容和资料,尽在聚客AI学院。



