传统神经网络(如MLP、CNN)的致命缺陷:
无法处理变长序列数据(如文本、语音、时间序列)
缺乏时序记忆能力,每个输入被独立处理
示例对比:
输入句子 "我爱人工智能"
CNN:识别局部词组(如"爱人工")但丢失顺序信息
RNN:逐词处理并传递上下文("我→爱→人工→智能")
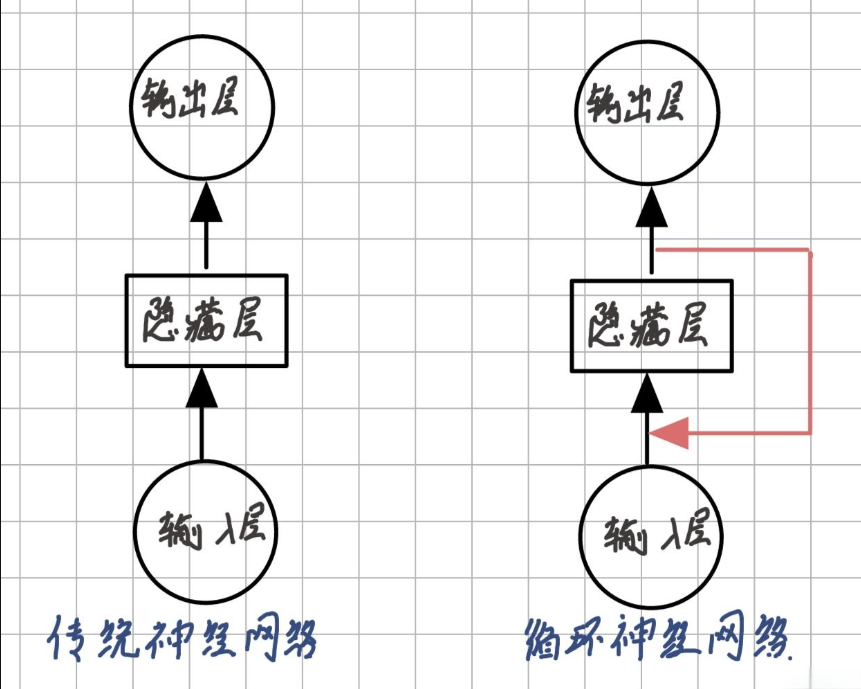
RNN通过循环单元在不同时间步共享参数,维护隐藏状态(Hidden State)传递时序信息:
时间步t的计算:
h_t = σ(W_{hh}h_{t-1} + W_{xh}x_t + b_h)
y_t = W_{hy}h_t + b_y其中:
ht:当前隐藏状态
σ:激活函数(通常为tanh)
W:权重矩阵
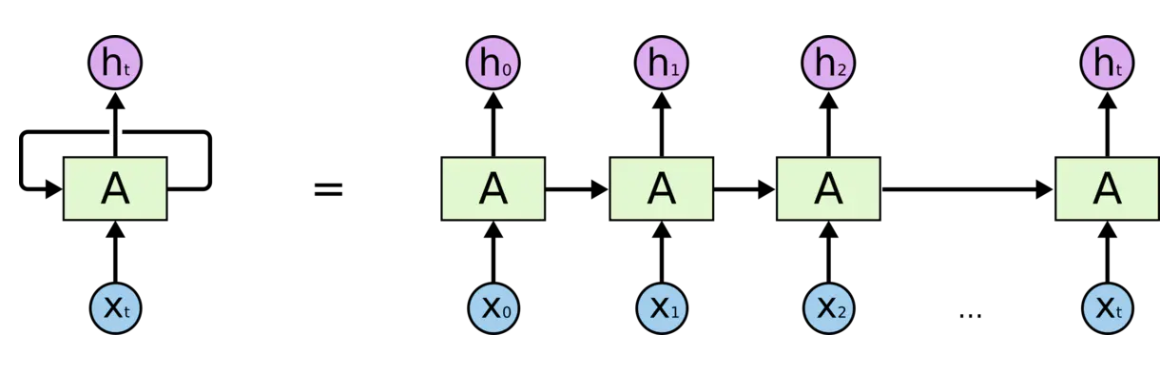
前向传播:

反向传播(BPTT):
通过时间展开的网络计算梯度:
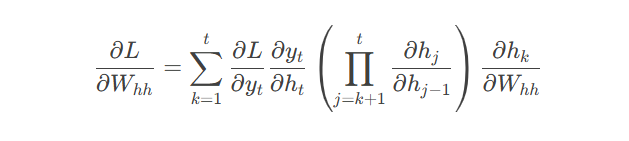
现象:早期时间步信息被后期信息淹没
案例:在句子 "动物保护组织反对用____做实验" 中,RNN可能遗忘"动物"导致填入错误答案
随时间步增加,梯度呈指数衰减:

若 ∣Whh∣<1,梯度趋向于0
若 ∣Whh∣>1,梯度呈指数增长,导致数值溢出
代码示例:梯度消失可视化
import torch
import matplotlib.pyplot as plt
# 模拟梯度传播
T = 50 # 时间步长
W = torch.tensor([[0.6]]) # 权重矩阵
grads = []
current_grad = 1.0
for t in range(T):
current_grad *= W.item()
grads.append(current_grad)
plt.plot(grads)
plt.title("Gradient Vanishing (W=0.6)")
plt.show()输出图示:梯度值随步长指数下降曲线
模型表现:
无法学习长距离依赖(如文本生成时忘记开头设定)
参数更新停滞,损失函数几乎不变
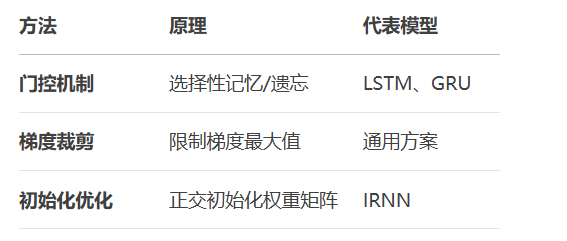
代码示例:LSTM实现
import torch.nn as nn class LSTMModel(nn.Module): def __init__(self, input_size, hidden_size): super().__init__() self.lstm = nn.LSTM(input_size, hidden_size, batch_first=True) self.fc = nn.Linear(hidden_size, 1) def forward(self, x): # x shape: (batch_size, seq_len, input_size) out, (h_n, c_n) = self.lstm(x) return self.fc(out[:, -1, :]) # 使用示例 model = LSTMModel(input_size=10, hidden_size=32) inputs = torch.randn(2, 20, 10) # batch=2, seq_len=20 output = model(inputs) print(output.shape) # torch.Size([2, 1])
注:本文代码需安装以下依赖:
pip install torch matplotlib
更多AI大模型应用开发学习内容,尽在聚客AI学院。



