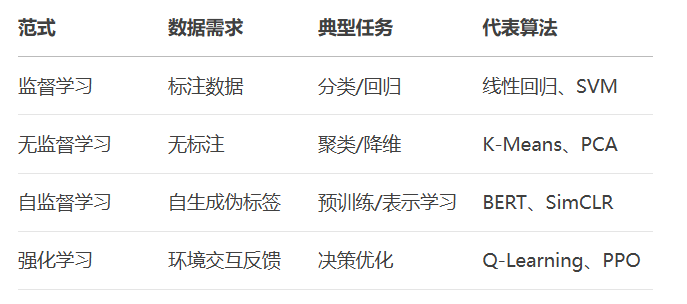
在给定输入-输出对(X,Y)的条件下,学习从输入到输出的映射函数f:X→Y。
分类:垃圾邮件检测(准确率>99%)
回归:房价预测(MAE<$10,000)
序列标注:命名实体识别(F1>0.92)
2.3.1 线性回归
from sklearn.linear_model import LinearRegression import numpy as np # 生成数据 X = np.array([[1], [2], [3]]) y = np.array([2, 4, 6]) # 训练模型 model = LinearRegression() model.fit(X, y) # 预测 print(model.predict([[4]])) # 输出: [8.]
2.3.2 决策树分类
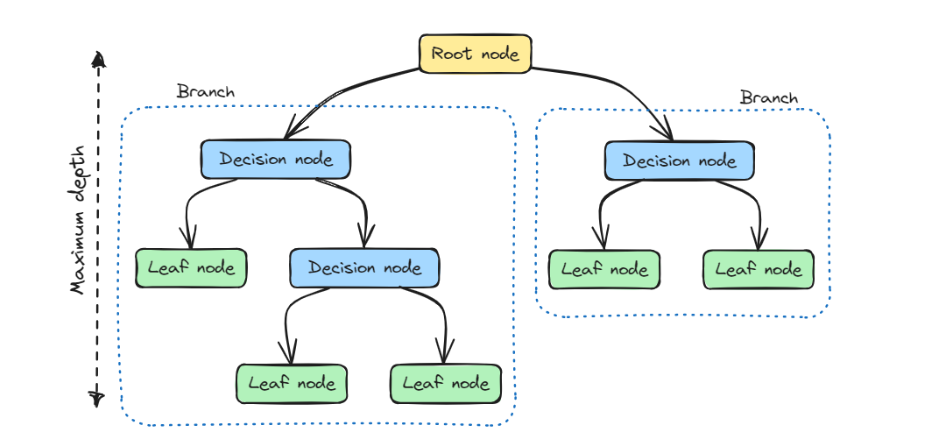
from sklearn.tree import DecisionTreeClassifier from sklearn.datasets import load_iris # 加载数据 iris = load_iris() X, y = iris.data, iris.target # 训练模型 clf = DecisionTreeClassifier(max_depth=2) clf.fit(X, y) # 可视化决策树 from sklearn.tree import plot_tree plot_tree(clf, feature_names=iris.feature_names)
从未标注数据中挖掘隐藏模式,无需人工标注指导。
客户分群:电商用户行为聚类
异常检测:金融交易异常识别(检出率>85%)
数据压缩:MNIST图像从784维降至2维可视化
3.3.1 K-Means聚类
from sklearn.cluster import KMeans import matplotlib.pyplot as plt # 生成数据 X = np.random.rand(300,2) # 聚类 kmeans = KMeans(n_clusters=3) labels = kmeans.fit_predict(X) # 可视化 plt.scatter(X[:,0], X[:,1], c=labels) plt.show()
3.3.2 PCA降维
from sklearn.decomposition import PCA # MNIST降维 pca = PCA(n_components=2) X_pca = pca.fit_transform(X) # 可视化 plt.scatter(X_pca[:,0], X_pca[:,1], c=y) plt.show()
通过设计代理任务从无标注数据中自动生成监督信号,学习通用表示。
文本预训练:BERT的掩码语言建模
图像对比学习:SimCLR的特征对齐
视频时序预测:预测下一帧
代码示例:BERT掩码预测
from transformers import BertTokenizer, BertForMaskedLM
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForMaskedLM.from_pretrained('bert-base-uncased')
input_text = "The capital of France is [MASK]."
inputs = tokenizer(input_text, return_tensors='pt')
outputs = model(**inputs)
predicted_index = outputs.logits[0, 4].argmax()
print(tokenizer.decode([predicted_index])) # 输出: paris智能体通过与环境交互,根据奖励信号优化策略π:S→A。
游戏AI:AlphaGo、Dota2 OpenAI Five
机器人控制:机械臂抓取(成功率>95%)
资源调度:云计算任务分配
5.3.1 Q-Learning
import gym
import numpy as np
env = gym.make('FrozenLake-v1')
Q = np.zeros([env.observation_space.n, env.action_space.n])
# 训练参数
alpha = 0.8
gamma = 0.95
num_episodes = 2000
for i in range(num_episodes):
state = env.reset()
done = False
while not done:
action = np.argmax(Q[state,:] + np.random.randn(1,env.action_space.n)*(1./(i+1)))
next_state, reward, done, _ = env.step(action)
Q[state,action] += alpha * (reward + gamma*np.max(Q[next_state,:]) - Q[state,action])
state = next_state5.3.2 深度强化学习(DQN)
import torch import torch.nn as nn import torch.optim as optim class DQN(nn.Module): def __init__(self, input_dim, output_dim): super().__init__() self.fc = nn.Sequential( nn.Linear(input_dim, 128), nn.ReLU(), nn.Linear(128, output_dim) ) def forward(self, x): return self.fc(x) # 使用PyTorch实现经验回放与目标网络...
注:本文代码需安装以下依赖:
pip install scikit-learn matplotlib gym transformers torch
更多AI大模型应用开发学习内容,尽在聚客AI学院。



