神经网络训练是通过调整权重参数,使模型输出逐渐逼近真实值的过程。其核心流程可概括为:
数据输入 → 前向传播 → 损失计算 → 反向传播 → 参数更新
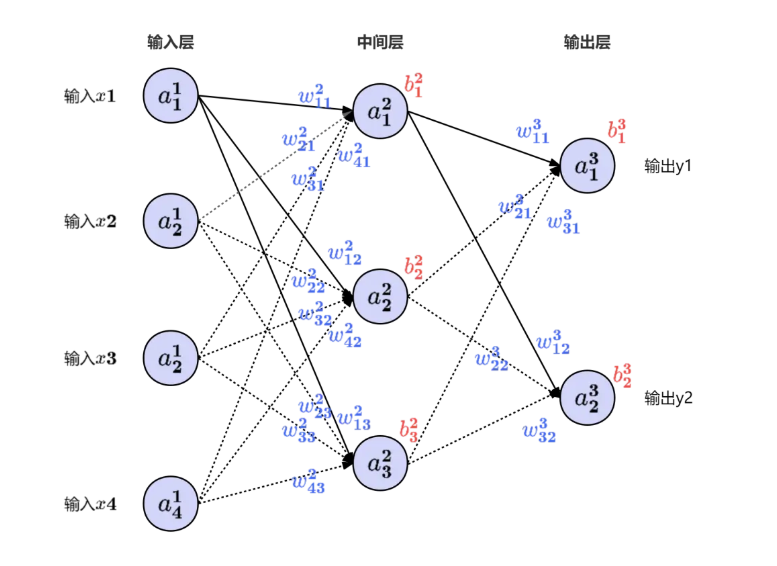
输入数据逐层通过神经网络,最终得到预测输出:

其中:
l:层编号
W:权重矩阵
b:偏置项
σ:激活函数
代码示例:手动实现前向传播
import torch import torch.nn as nn # 定义3层网络 class SimpleNet(nn.Module): def __init__(self): super().__init__() self.fc1 = nn.Linear(784, 256) # 输入层→隐层 self.fc2 = nn.Linear(256, 10) # 隐层→输出层 self.relu = nn.ReLU() def forward(self, x): x = self.relu(self.fc1(x)) x = self.fc2(x) return x # 测试 model = SimpleNet() input_data = torch.randn(64, 784) # batch_size=64 output = model(input_data) print(output.shape) # torch.Size([64, 10])
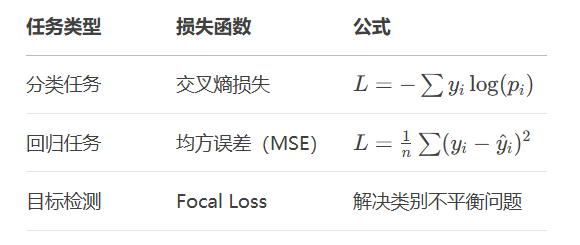
代码示例:交叉熵损失计算
criterion = nn.CrossEntropyLoss() loss = criterion(output, target_labels)
通过计算损失函数对参数的梯度,沿负梯度方向更新参数:
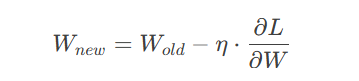
其中 η 为学习率(Learning Rate)。
代码示例:手动实现梯度更新
learning_rate = 0.01 for param in model.parameters(): param.data -= learning_rate * param.grad
4.2 优化器变体
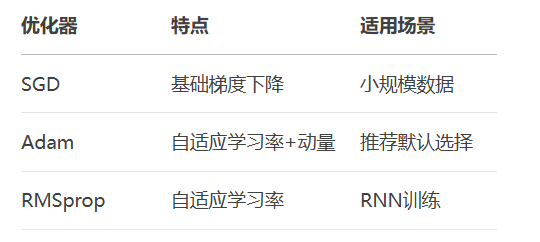
代码示例:Adam优化器使用
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) optimizer.step()
大批量(如256):内存占用高,收敛稳定
小批量(如32):梯度噪声大,可能跳出局部最优
经验公式:
GPU显存需求≈4×
学习率衰减:
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
预热策略(Warmup):前5%训练步线性增加学习率
早停法(Early Stopping):验证集损失连续3次不下降时终止训练
L1:促进稀疏性
L2:防止过拟合
# L2正则化 optimizer = torch.optim.SGD(model.parameters(), lr=0.01, weight_decay=1e-4)
随机屏蔽神经元,增强泛化能力:
self.dropout = nn.Dropout(p=0.5) x = self.dropout(x)

代码示例:GELU实现
import torch.nn.functional as F x = F.gelu(x)
计算梯度从输出层逐层回传:
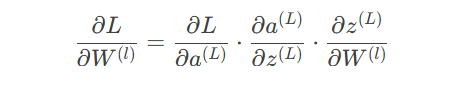
现象:深层网络中出现梯度指数级缩小/增大
检测方法:
print(torch.abs(param.grad).mean()) # 监控梯度均值
权重初始化:
nn.init.kaiming_normal_(self.fc1.weight, mode='fan_in')
归一化技术:
Batch Norm:对每批数据归一化
Layer Norm:适用于RNN/Transformer
代码示例:Batch Normalization
self.bn = nn.BatchNorm1d(256) x = self.bn(x)
import torch
from torch import nn, optim
from torch.utils.data import DataLoader
# 数据加载
train_loader = DataLoader(dataset, batch_size=64, shuffle=True)
# 模型定义
model = SimpleNet()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练循环
for epoch in range(100):
for inputs, labels in train_loader:
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
print(f'Epoch {epoch+1}, Loss: {loss.item():.4f}')注:本文代码基于PyTorch 2.0实现,运行前请安装依赖:
pip install torch torchvision matplotlib
更多AI大模型应用开发学习内容,尽在聚客AI学院。



