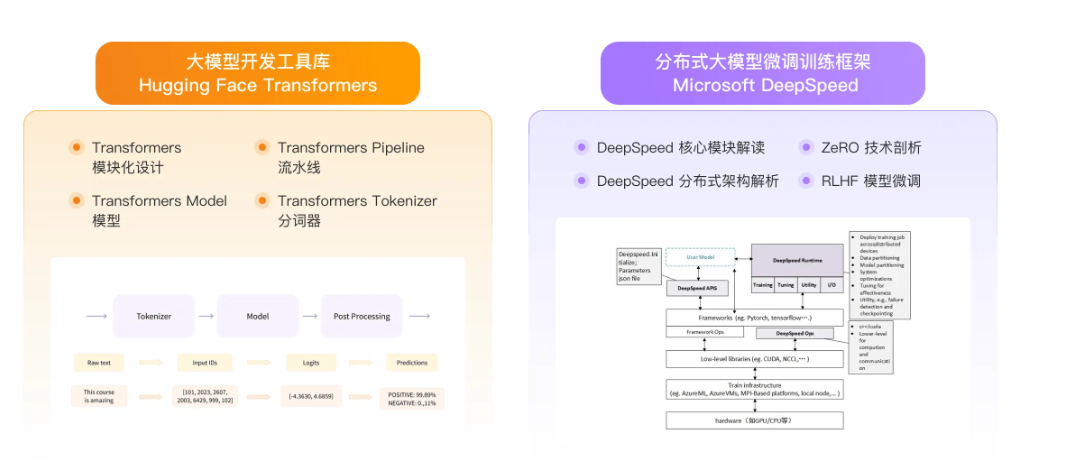
大语言模型(LLM)如GPT-4、LLaMA通过预训练掌握了通用知识,但在特定领域(医疗、法律、金融)表现不足。微调(Fine-tuning)通过领域数据注入和任务适配,使模型获得专业能力。
核心优势:
高效利用数据:千级样本即可显著提升效果
降低推理成本:专用模型比通用模型参数量更少
保护隐私:私有数据无需上传至云端
更新模型全部参数,适合数据量充足(百万级)的场景。
缺点:显存占用高(如175B模型需超2TB显存),易过拟合。
在预训练基础上分阶段更新部分层,平衡效果与资源消耗。
仅调整特定模块(如注意力层、FFN层),典型代表:
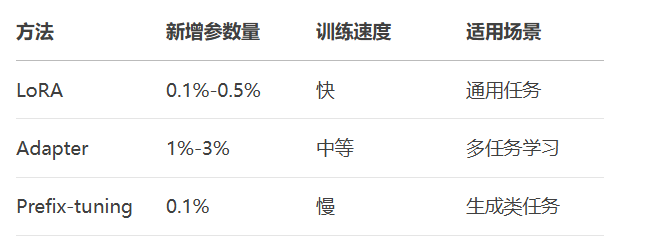
LoRA(Low-Rank Adaptation):低秩矩阵注入
Adapter:插入小型神经网络
Prefix-tuning:优化提示向量
代码示例:全量微调配置(PyTorch)
from transformers import AutoModelForCausalLM, TrainingArguments
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b")
args = TrainingArguments(
output_dir="./output",
per_device_train_batch_size=4,
gradient_accumulation_steps=8, # 显存不足时累计梯度
num_train_epochs=3,
learning_rate=2e-5
)通过冻结原始参数,仅训练少量新增参数(通常<1%总参数量),实现高效适配。
技术对比:
高质量数据格式示例(JSON):
{
"instruction": "生成一段产品描述",
"input": "品牌:AromaTech,产品:无线蓝牙耳机,卖点:降噪、30小时续航",
"output": "AromaTech新款无线蓝牙耳机搭载主动降噪技术..."
}关键原则:
指令多样性:覆盖不同任务类型(问答、生成、分类)
数据平衡:各类样本比例均衡
标注一致性:输出格式标准化
对权重矩阵W∈Rd×k,引入低秩分解:

其中B∈Rd×r,A∈Rr×k,秩r≪min(d,k)。

代码示例:使用Hugging Face PEFT库
from peft import LoraConfig, get_peft_model
from transformers import AutoModelForCausalLM
# 加载基础模型
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b")
# 配置LoRA
lora_config = LoraConfig(
r=8, # 秩
lora_alpha=32, # 缩放系数
target_modules=["q_proj", "v_proj"], # 注入位置
lora_dropout=0.05,
bias="none"
)
# 创建可训练模型
model = get_peft_model(model, lora_config)
model.print_trainable_parameters() # 输出:trainable params: 8,388,608 || all params: 6,742,609,920# 加载多个适配器
model.load_adapter("adapter1", adapter_name="medical")
model.load_adapter("adapter2", adapter_name="legal")
# 动态切换
model.set_adapter("medical") # 激活医疗领域适配器以Llama-7B为例:
全量微调:约112GB显存(FP32)
LoRA微调:约24GB显存(FP16 + 梯度检查点)
优化公式:
显存占用≈4×参数量×批次大小
代码示例:启用混合精度训练
training_args = TrainingArguments( fp16=True, fp16_opt_level="O2", # 优化级别 gradient_checkpointing=True # 梯度检查点减少显存 )
代码示例:8bit模型加载
from transformers import BitsAndBytesConfig quant_config = BitsAndBytesConfig( load_in_8bit=True, llm_int8_threshold=6.0 ) model = AutoModelForCausalLM.from_pretrained( "meta-llama/Llama-2-7b", quantization_config=quant_config )
现象:损失值变为NaN
解决:
缩放损失函数(如使用梯度缩放)
调整优化器参数(如Adam的epsilon=1e-7)
现象:CUDA out of memory
解决:
减小批次大小(batch_size=2 → 1)
开启梯度累积(gradient_accumulation_steps=4)
使用DeepSpeed ZeRO-3优化
代码示例:DeepSpeed配置
{
"train_batch_size": 16,
"gradient_accumulation_steps": 4,
"zero_optimization": {
"stage": 3,
"offload_optimizer": {
"device": "cpu"
}
}
}注:本文代码基于PyTorch 2.0+和Transformers 4.30+版本,完整项目示例需配置至少16GB显存的GPU环境。更多AI大模型应用开发学习内容,尽在聚客AI学院。



