全参数微调 (Full Fine-tuning)
# Hugging Face全参数微调示例
from transformers import AutoModelForSequenceClassification, TrainingArguments
model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased")
args = TrainingArguments(
output_dir="output",
per_device_train_batch_size=32,
num_train_epochs=3
)
trainer = Trainer(model, args, train_dataset)
trainer.train()痛点:显存占用大(如Llama2-7B需4×24G GPU)
参数高效微调 (PEFT)
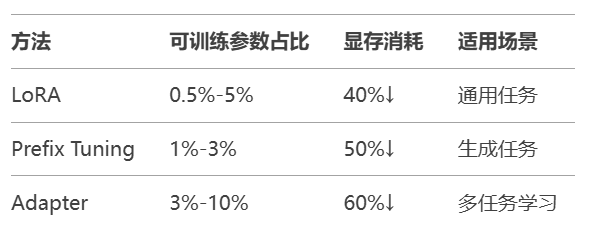
# LoRA微调实战 from peft import LoraConfig, get_peft_model config = LoraConfig( r=8, target_modules=["q_proj", "v_proj"], lora_alpha=32 ) model = get_peft_model(base_model, config)
量化类型对比
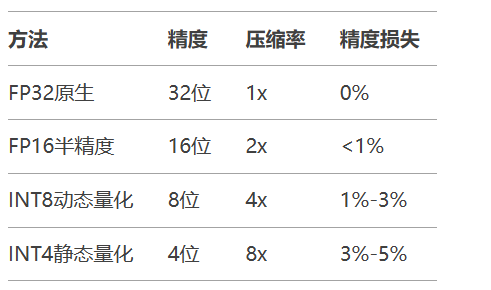
# 使用Optimum进行量化
from optimum.onnxruntime import ORTQuantizer
quantizer = ORTQuantizer.from_pretrained("bert-base-uncased")
quantizer.export(
onnx_model_path="model.onnx",
onnx_quantized_model_path="model_quant.onnx",
quantization_type="dynamic"
)剪枝流程
重要性评估(基于梯度/激活值)
移除冗余神经元/注意力头
微调恢复精度
# 使用Torch Prune剪枝 import torch_pruning as tp strategy = tp.strategy.L1Strategy() pruner = tp.pruner.MagnitudePruner( model, strategy, target_sparsity=0.5 ) pruner.step()
蒸馏架构
教师模型(大) → 知识迁移 → 学生模型(小) ↑ 蒸馏损失(KL散度)
实战代码
from transformers import DistilBertForSequenceClassification
teacher = BertForSequenceClassification.from_pretrained("bert-base")
student = DistilBertForSequenceClassification.from_pretrained("distilbert-base")
loss = KLDivLoss(
student_logits,
teacher_logits.detach(),
temperature=2.0
)# 使用LoRA微调ChatGLM
model = AutoModel.from_pretrained("chatglm3-6b")
peft_config = LoraConfig(task_type="CAUSAL_LM")
lora_model = get_peft_model(model, peft_config)
# 加载客服对话数据集
trainer = SFTTrainer(
model=lora_model,
train_dataset=dataset,
max_seq_length=512
)
trainer.train()优化策略组合
graph LR A[原始模型] --> B(动态量化) B --> C(注意力头剪枝) C --> D(知识蒸馏) D --> E[轻量模型]
量化部署代码
# 转换ONNX格式并量化
model.save_pretrained("chatglm-optimized")
quantizer = ORTQuantizer.from_pretrained("chatglm-optimized")
quantizer.quantize("chatglm-int8.onnx")
# Triton推理服务配置
config = """
platform: "onnxruntime_onnx"
max_batch_size: 32
input [
{ name: "input_ids", data_type: TYPE_INT64, dims: [ -1 ] }
]
output [
{ name: "logits", data_type: TYPE_FP32, dims: [ -1, 50257 ] }
]
"""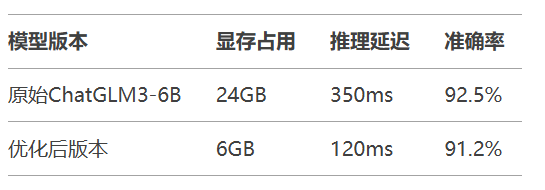
优化效果:
显存需求降低75%
推理速度提升3倍
精度损失仅1.3%
自适应微调:根据硬件自动选择最优微调策略
稀疏计算加速:利用剪枝结构实现硬件级加速
端侧推理芯片:NPU针对量化模型指令集优化
结语:掌握“微调-压缩-部署”全链路技术,是构建企业级大模型应用的核心竞争力。建议从垂直场景切入,通过工具链组合实现最佳性价比。



