本文将通过代码实战带你快速掌握NLP三大核心任务,使用Hugging Face Transformers库实现工业级AI应用开发。
pip install transformers datasets torch tensorboard
from datasets import load_dataset
from transformers import AutoTokenizer
dataset = load_dataset("imdb")
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)from transformers import AutoModelForSequenceClassification, TrainingArguments, Trainer model = AutoModelForSequenceClassification.from_pretrained( "distilbert-base-uncased", num_labels=2 ) training_args = TrainingArguments( output_dir="./results", evaluation_strategy="epoch", learning_rate=2e-5, per_device_train_batch_size=16, num_train_epochs=3, ) trainer = Trainer( model=model, args=training_args, train_dataset=tokenized_datasets["train"], eval_dataset=tokenized_datasets["test"], ) trainer.train()
from transformers import pipeline
classifier = pipeline("text-classification", model=model, tokenizer=tokenizer)
result = classifier("This movie was absolutely fantastic!")
print(result) # [{'label': 'POSITIVE', 'score': 0.999}]
dataset = load_dataset("squad")
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
def preprocess_function(examples):
questions = [q.strip() for q in examples["question"]]
inputs = tokenizer(
questions,
examples["context"],
max_length=384,
truncation="only_second",
return_offsets_mapping=True,
padding="max_length",
)
return inputs
tokenized_squad = dataset.map(preprocess_function, batched=True)from transformers import AutoModelForQuestionAnswering
model = AutoModelForQuestionAnswering.from_pretrained("distilbert-base-uncased")
training_args = TrainingArguments(
output_dir="./qa_results",
evaluation_strategy="epoch",
learning_rate=3e-5,
per_device_train_batch_size=12,
num_train_epochs=2,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_squad["train"],
eval_dataset=tokenized_squad["validation"],
)
trainer.train()question = "What does NLP stand for?"
context = "Natural Language Processing (NLP) is a subfield of artificial intelligence."
qa_pipeline = pipeline("question-answering", model=model, tokenizer=tokenizer)
result = qa_pipeline(question=question, context=context)
print(result)
# {'score': 0.982, 'start': 0, 'end': 24, 'answer': 'Natural Language Processing'}dataset = load_dataset("conll2003")
tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")
label_list = dataset["train"].features["ner_tags"].feature.names
def tokenize_and_align_labels(examples):
tokenized_inputs = tokenizer(
examples["tokens"],
truncation=True,
is_split_into_words=True
)
labels = []
for i, label in enumerate(examples["ner_tags"]):
word_ids = tokenized_inputs.word_ids(batch_index=i)
previous_word_idx = None
label_ids = []
for word_idx in word_ids:
if word_idx is None:
label_ids.append(-100)
elif word_idx != previous_word_idx:
label_ids.append(label[word_idx])
else:
label_ids.append(-100)
previous_word_idx = word_idx
labels.append(label_ids)
tokenized_inputs["labels"] = labels
return tokenized_inputs
tokenized_dataset = dataset.map(tokenize_and_align_labels, batched=True)from transformers import AutoModelForTokenClassification model = AutoModelForTokenClassification.from_pretrained( "bert-base-cased", num_labels=len(label_list) training_args = TrainingArguments( output_dir="./ner_results", evaluation_strategy="epoch", learning_rate=2e-5, per_device_train_batch_size=16, num_train_epochs=3, ) trainer = Trainer( model=model, args=training_args, train_dataset=tokenized_dataset["train"], eval_dataset=tokenized_dataset["validation"], ) trainer.train()
from transformers import pipeline
ner_pipeline = pipeline("ner", model=model, tokenizer=tokenizer)
sample_text = "Apple was founded by Steve Jobs in Cupertino, California."
entities = ner_pipeline(sample_text)
for entity in entities:
print(f"{entity['word']} -> {label_list[entity['entity'][-1]]}")
# Apple -> B-ORG
# Steve Jobs -> B-PER
# Cupertino -> B-LOC
# California -> B-LOC迁移学习优势:使用预训练模型可节省90%训练时间
动态填充:使用DataCollator提升训练效率
混合精度训练:添加fp16=True参数加速训练
学习率调度:采用线性衰减策略更稳定收敛
早停机制:监控验证集损失防止过拟合
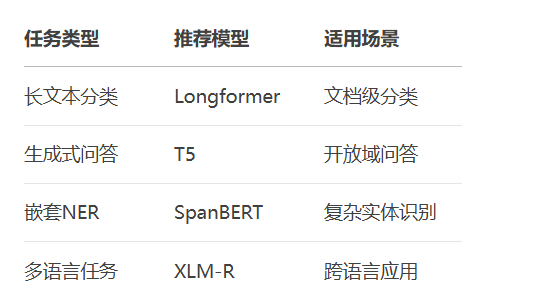
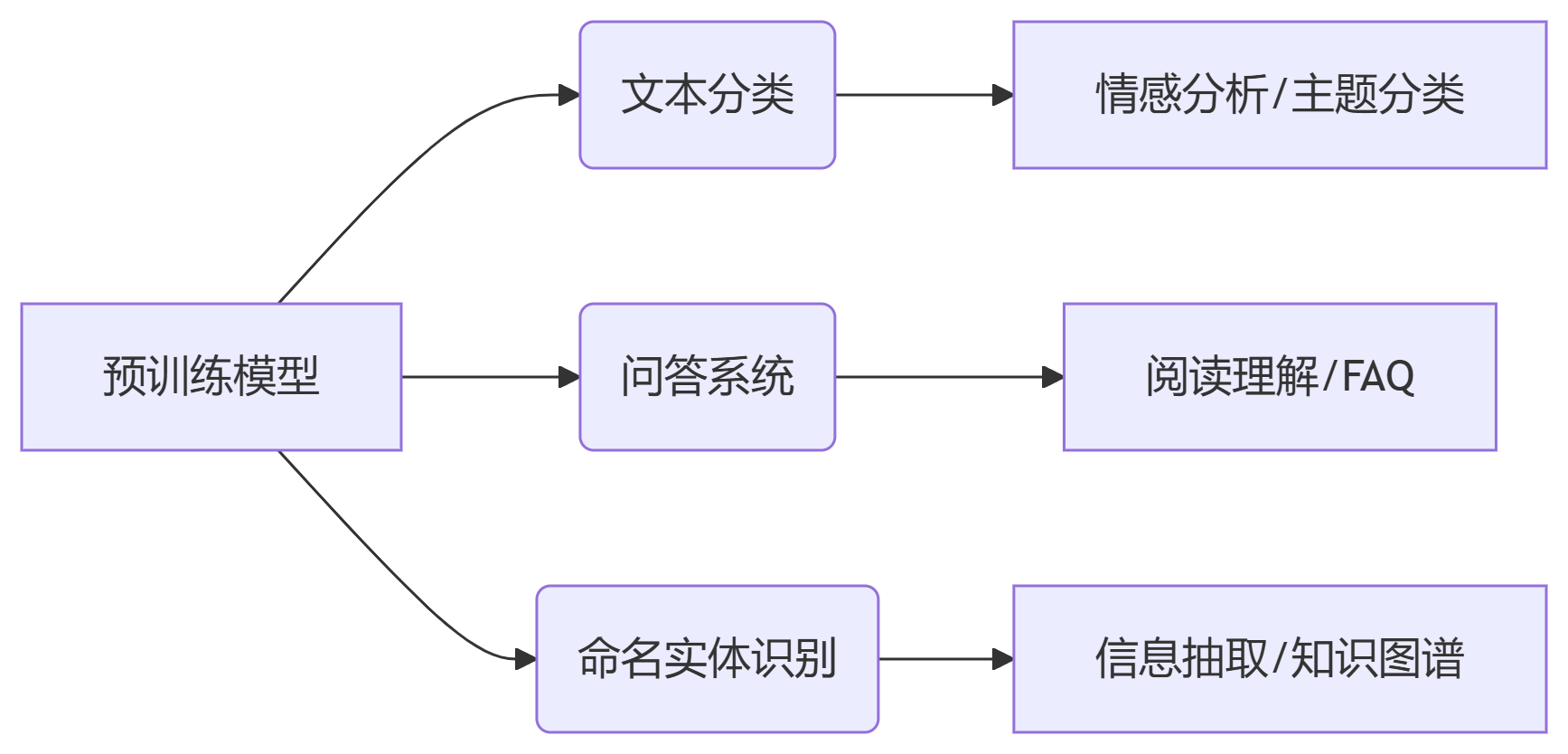
关键提示:实践时注意调整超参数(batch size、学习率)以适应你的硬件配置,小显存设备建议使用distilbert等轻量模型。更多AI大模型应用开发学习视频内容和资料,尽在聚客AI学院。



