本文全面解析BERT的核心机制,深入讲解Masked Language Modeling和Next Sentence Prediction预训练任务,通过数学原理、架构设计和代码实现揭示BERT如何学习通用语言表示。

import torch
from transformers import BertModel, BertTokenizer
# 加载预训练BERT模型
model = BertModel.from_pretrained('bert-base-uncased')
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# 示例文本
text = "The cat sat on the mat."
inputs = tokenizer(text, return_tensors='pt')
# 前向传播
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
print("输入文本:", text)
print("词嵌入形状:", last_hidden_states.shape) # [batch_size, seq_len, hidden_size]BERT核心创新:
深度双向Transformer:同时利用左右上下文
预训练+微调范式:统一架构适应多任务
无监督预训练:利用大规模未标注数据
上下文相关表示:相同词在不同语境有不同表示
from transformers import BertConfig
# 查看BERT-base配置
config = BertConfig.from_pretrained('bert-base-uncased')
print(config)
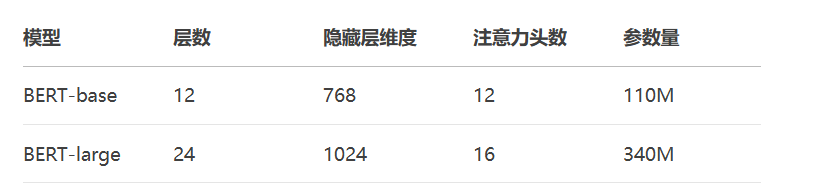
# 架构关键参数:
# hidden_size=768 # 隐藏层维度
# num_hidden_layers=12 # Transformer层数
# num_attention_heads=12 # 注意力头数
# intermediate_size=3072 # FFN中间层维度
# max_position_embeddings=512 # 最大位置编码BERT模型规格:
2.2 输入表示
# 输入嵌入可视化
input_ids = inputs['input_ids']
token_type_ids = inputs['token_type_ids']
attention_mask = inputs['attention_mask']
# 获取各组成部分
token_embeddings = model.embeddings.word_embeddings(input_ids)
position_embeddings = model.embeddings.position_embeddings(torch.arange(input_ids.size(1)))
segment_embeddings = model.embeddings.token_type_embeddings(token_type_ids)
# 组合嵌入
embeddings = token_embeddings + position_embeddings + segment_embeddings
embeddings = model.embeddings.LayerNorm(embeddings)
embeddings = model.embeddings.dropout(embeddings)
print("词嵌入形状:", token_embeddings.shape)
print("位置嵌入形状:", position_embeddings.shape)
print("段落嵌入形状:", segment_embeddings.shape)
print("最终嵌入形状:", embeddings.shape)BERT输入嵌入:
Token Embeddings:词嵌入(WordPiece分词)
Position Embeddings:位置编码(学习得到)
Segment Embeddings:段落标记(区分句子A/B)
[CLS] Sentence A [SEP] Sentence B [SEP]
from transformers import BertForMaskedLM
# 加载MLM模型
mlm_model = BertForMaskedLM.from_pretrained('bert-base-uncased')
# 掩码示例
masked_text = "The cat [MASK] on the mat."
inputs = tokenizer(masked_text, return_tensors='pt')
# 预测掩码位置
with torch.no_grad():
outputs = mlm_model(**inputs)
logits = outputs.logits
# 获取掩码位置索引
mask_token_index = (inputs.input_ids == tokenizer.mask_token_id)[0].nonzero(as_tuple=True)[0]
# 预测前5个候选
predicted_tokens = logits[0, mask_token_index].topk(5).indices[0].tolist()
predicted_words = [tokenizer.decode([token]) for token in predicted_tokens]
print(f"掩码预测: '{masked_text}' → {predicted_words}")
# 典型输出: ['sat', 'sits', 'rested', 'lay', 'was']def mlm_mask_tokens(inputs, tokenizer, mlm_probability=0.15):
"""BERT动态掩码策略"""
labels = inputs.clone()
probability_matrix = torch.full(labels.shape, mlm_probability)
# 特殊标记不掩码
special_tokens_mask = [
tokenizer.get_special_tokens_mask(val, already_has_special_tokens=True)
for val in labels.tolist()
]
special_tokens_mask = torch.tensor(special_tokens_mask, dtype=torch.bool)
probability_matrix.masked_fill_(special_tokens_mask, value=0.0)
# 生成掩码索引
masked_indices = torch.bernoulli(probability_matrix).bool()
labels[~masked_indices] = -100 # 损失函数忽略
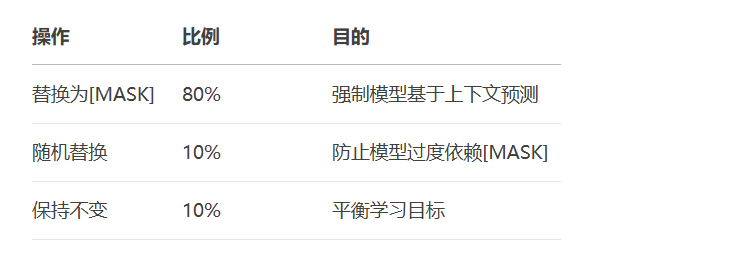
# 80%替换为[MASK]
indices_replaced = torch.bernoulli(torch.full(labels.shape, 0.8)).bool() & masked_indices
inputs[indices_replaced] = tokenizer.mask_token_id
# 10%随机替换
indices_random = torch.bernoulli(torch.full(labels.shape, 0.5)).bool()
indices_random = indices_random & masked_indices & ~indices_replaced
random_words = torch.randint(len(tokenizer), labels.shape, dtype=torch.long)
inputs[indices_random] = random_words[indices_random]
return inputs, labels
# 示例应用
original_inputs = torch.tensor([[101, 2023, 2003, 1037, 2307, 1029, 102]])
masked_inputs, mlm_labels = mlm_mask_tokens(original_inputs.clone(), tokenizer)
print("原始输入:", tokenizer.decode(original_inputs[0]))
print("掩码后输入:", tokenizer.decode(masked_inputs[0]))
print("MLM标签:", mlm_labels.tolist())MLM掩码策略:
from transformers import BertForNextSentencePrediction
# 加载NSP模型
nsp_model = BertForNextSentencePrediction.from_pretrained('bert-base-uncased')
# 创建句子对
sentence_A = "The cat sat on the mat."
sentence_B = "It was very comfortable."
sentence_C = "The sky is blue today."
# 准备输入
inputs_AB = tokenizer(sentence_A, sentence_B, return_tensors='pt')
inputs_AC = tokenizer(sentence_A, sentence_C, return_tensors='pt')
# 预测关系
with torch.no_grad():
outputs_AB = nsp_model(**inputs_AB)
outputs_AC = nsp_model(**inputs_AC)
# 解析结果
def parse_nsp(output):
probabilities = torch.softmax(output.logits, dim=1)
return probabilities[0][0].item() # IsNextSentence概率
print(f"句子对A-B相关概率: {parse_nsp(outputs_AB):.2f}")
print(f"句子对A-C相关概率: {parse_nsp(outputs_AC):.2f}")
# 典型输出: A-B: 0.98, A-C: 0.02import random
def create_nsp_examples(sentences):
"""创建NSP训练样本"""
examples = []
for i in range(len(sentences)):
# 50%正样本:连续句子
if i < len(sentences)-1 and random.random() > 0.5:
next_sentence = sentences[i+1]
label = 1 # 连续
# 50%负样本:随机句子
else:
next_sentence = random.choice(sentences)
label = 0 # 不连续
examples.append((sentences[i], next_sentence, label))
return examples
# 示例文本
sentences = [
"The cat sat on the mat.",
"It seemed very comfortable.",
"Dogs are loyal animals.",
"Cats are more independent.",
"The sky was clear and blue."
]
# 创建样本
nsp_examples = create_nsp_examples(sentences)
for ex in nsp_examples[:3]:
print(f"句子A: {ex[0]}\n句子B: {ex[1]}\n标签: {'相关' if ex[2] else '不相关'}\n")NSP输入格式:
[CLS] Sentence A [SEP] Sentence B [SEP]
class BertPretrainingLoss(nn.Module):
"""BERT预训练损失函数"""
def __init__(self):
super().__init__()
self.mlm_loss = nn.CrossEntropyLoss(ignore_index=-100)
self.nsp_loss = nn.CrossEntropyLoss()
def forward(self, mlm_logits, nsp_logits, mlm_labels, nsp_labels):
# MLM损失
mlm_loss = self.mlm_loss(
mlm_logits.view(-1, mlm_logits.size(-1)),
mlm_labels.view(-1)
)
# NSP损失
nsp_loss = self.nsp_loss(nsp_logits, nsp_labels)
return mlm_loss + nsp_loss, mlm_loss, nsp_loss
# 模拟损失计算
batch_size = 32
seq_len = 128
vocab_size = 30522
mlm_logits = torch.randn(batch_size, seq_len, vocab_size)
nsp_logits = torch.randn(batch_size, 2)
mlm_labels = torch.full((batch_size, seq_len), -100) # 部分位置有标签
mlm_labels[0, 5] = 2023 # 示例标签
mlm_labels[1, 7] = 1037
nsp_labels = torch.randint(0, 2, (batch_size,)) # 二分类标签
loss_fn = BertPretrainingLoss()
total_loss, mlm_loss, nsp_loss = loss_fn(mlm_logits, nsp_logits, mlm_labels, nsp_labels)
print(f"总损失: {total_loss.item():.4f}, MLM损失: {mlm_loss.item():.4f}, NSP损失: {nsp_loss.item():.4f}")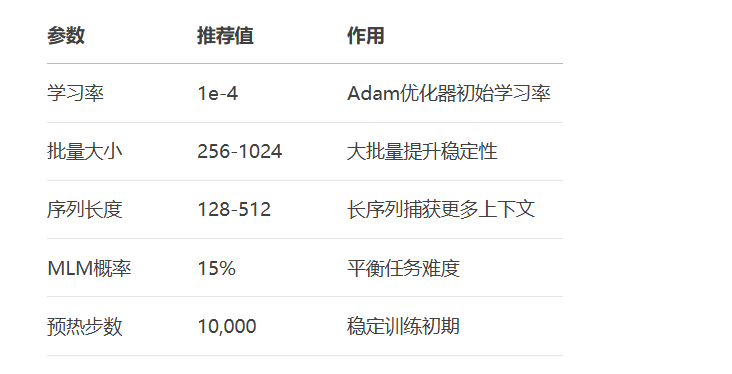
from transformers import BertForSequenceClassification
from datasets import load_dataset
# 加载数据集
dataset = load_dataset('glue', 'sst2')
train_dataset = dataset['train']
# 初始化模型
model = BertForSequenceClassification.from_pretrained(
'bert-base-uncased',
num_labels=2 # 二分类
)
# 微调训练
optimizer = torch.optim.AdamW(model.parameters(), lr=2e-5)
for epoch in range(3):
total_loss = 0
for i in range(0, len(train_dataset), 32):
# 获取批次数据
batch = train_dataset[i:i+32]
inputs = tokenizer(
batch['sentence'],
padding=True,
truncation=True,
return_tensors='pt'
)
labels = torch.tensor(batch['label'])
# 前向传播
outputs = model(**inputs, labels=labels)
loss = outputs.loss
# 反向传播
loss.backward()
optimizer.step()
optimizer.zero_grad()
total_loss += loss.item()
print(f"Epoch {epoch+1}, Avg Loss: {total_loss/(len(train_dataset)//32):.4f}")from transformers import BertForQuestionAnswering
# 加载QA模型
qa_model = BertForQuestionAnswering.from_pretrained('bert-base-uncased')
# 问答示例
context = "Albert Einstein was born in Ulm, Germany in 1879."
question = "Where was Einstein born?"
inputs = tokenizer(
question,
context,
return_tensors='pt',
max_length=512,
truncation=True
)
# 预测答案
with torch.no_grad():
outputs = qa_model(**inputs)
# 解析结果
start_logits = outputs.start_logits
end_logits = outputs.end_logits
start_idx = torch.argmax(start_logits)
end_idx = torch.argmax(end_logits) + 1
answer_tokens = inputs.input_ids[0][start_idx:end_idx]
answer = tokenizer.decode(answer_tokens)
print(f"问题: {question}")
print(f"答案: {answer}") # 输出: Ulm, Germany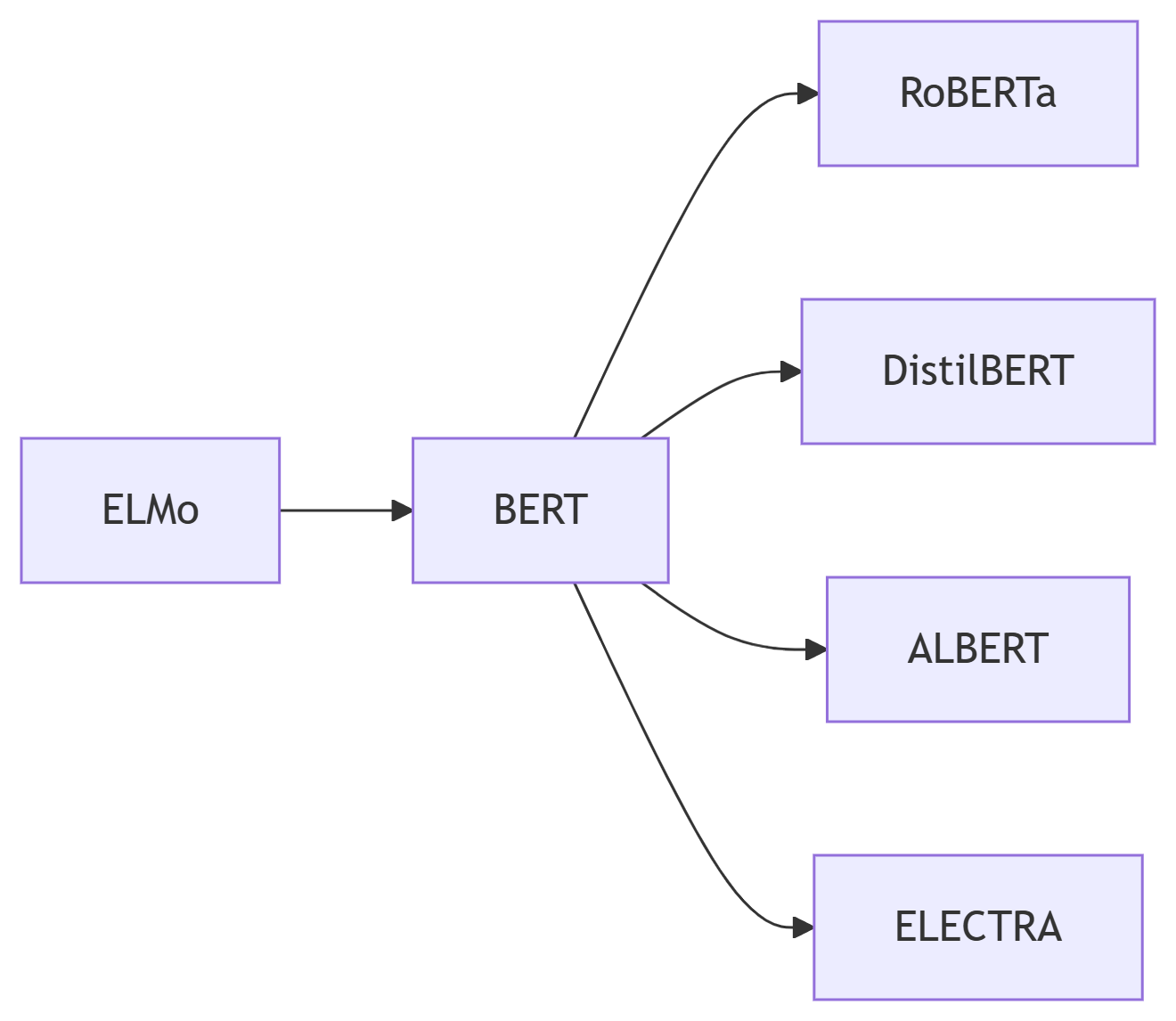


MLM核心机制:
# 动态掩码实现 inputs, labels = mlm_mask_tokens(inputs, tokenizer, mlm_prob=0.15)
NSP任务本质:
# 正样本: (句子A, 句子B, 1) # 负样本: (句子A, 随机句子, 0)
BERT输入三元组:
输入 = 词嵌入 + 位置嵌入 + 段落嵌入
微调最佳实践:
小学习率:2e-5到5e-5
短周期:3-5个epoch
梯度裁剪:防止梯度爆炸
权重衰减:正则化控制
应用领域:

通过深入理解BERT的预训练机制和架构设计,你将掌握现代NLP模型的基石,为学习和应用更先进的预训练模型奠定坚实基础!更多AI大模型应用开发学习视频内容和资料,尽在聚客AI学院。



