本文深入剖析大模型迁移学习核心机制,结合Hugging Face实战代码,掌握预训练模型高效应用之道。
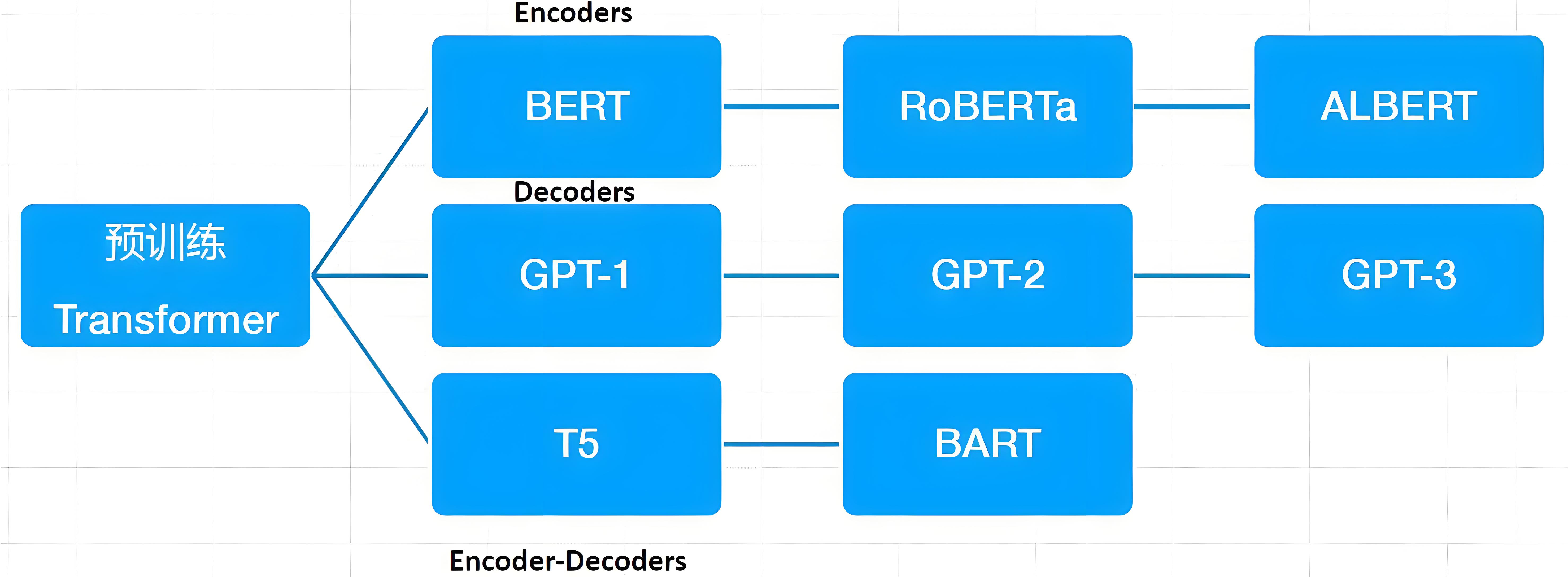
from transformers import AutoModel
# 加载三大类预训练模型
bert = AutoModel.from_pretrained("bert-base-uncased") # Encoder架构
gpt = AutoModel.from_pretrained("gpt2") # Decoder架构
t5 = AutoModel.from_pretrained("t5-base") # Encoder-Decoder2. 预训练任务原理
MLM (Masked Language Model)
输入: "The [MASK] sat on the mat." 标签: "cat"
NSP (Next Sentence Prediction)
句子A: "天空是蓝色的" 句子B: "狗在草地上奔跑" → 标签: NotNext 句子A: "COVID-19症状包括" 句子B: "发烧和咳嗽" → 标签: IsNext
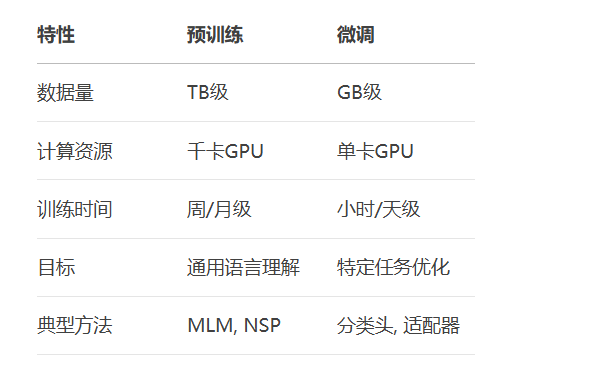
from transformers import Trainer, TrainingArguments # 配置训练参数 training_args = TrainingArguments( output_dir='./results', num_train_epochs=3, per_device_train_batch_size=16, learning_rate=5e-5, # 微调学习率通常为预训练的1/10 evaluation_strategy='epoch', save_strategy='epoch', fp16=True # 混合精度加速 ) # 创建训练器 trainer = Trainer( model=model, args=training_args, train_dataset=train_set, eval_dataset=val_set, compute_metrics=compute_accuracy # 自定义评估函数 ) # 执行微调 trainer.train()
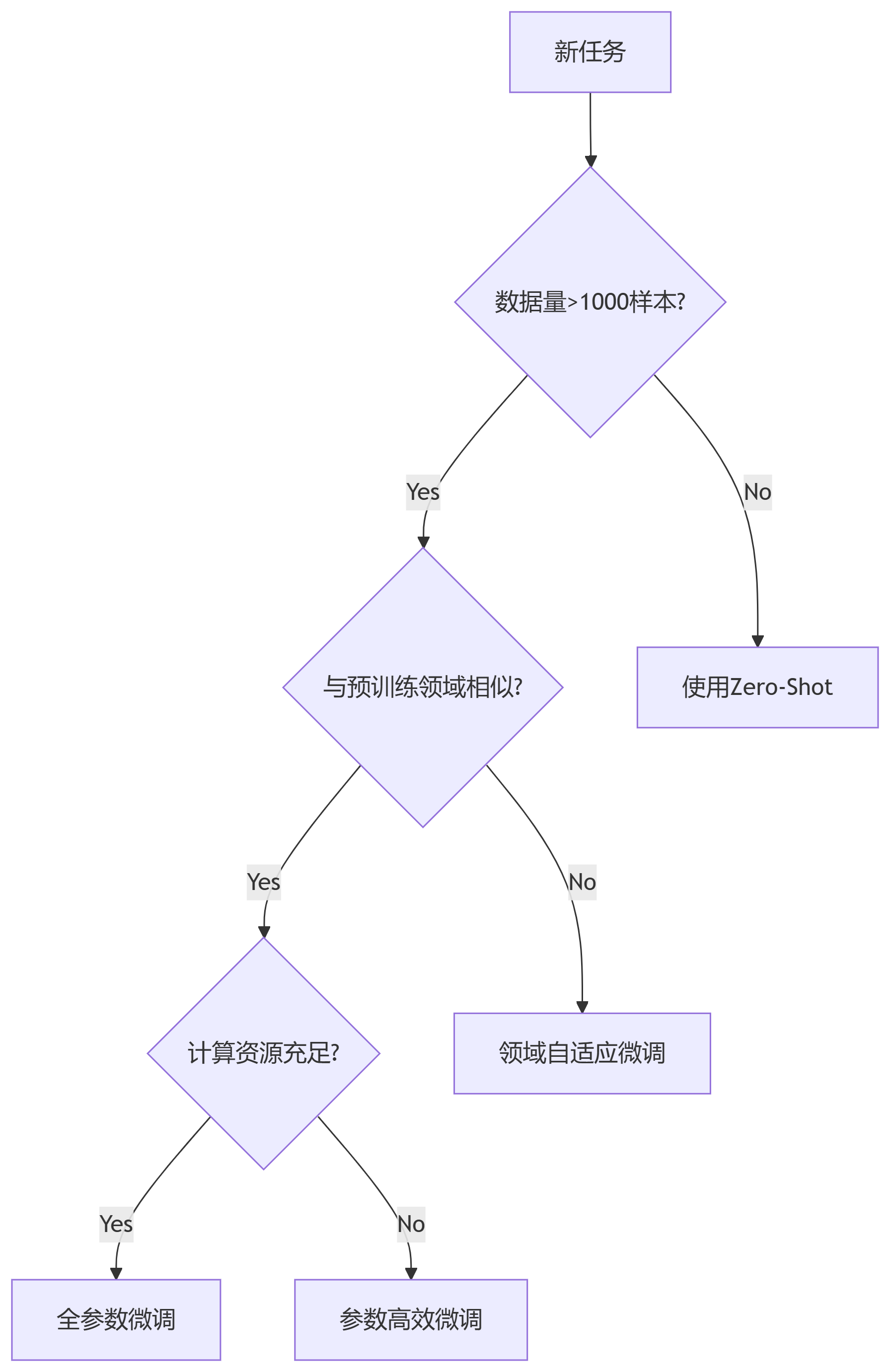
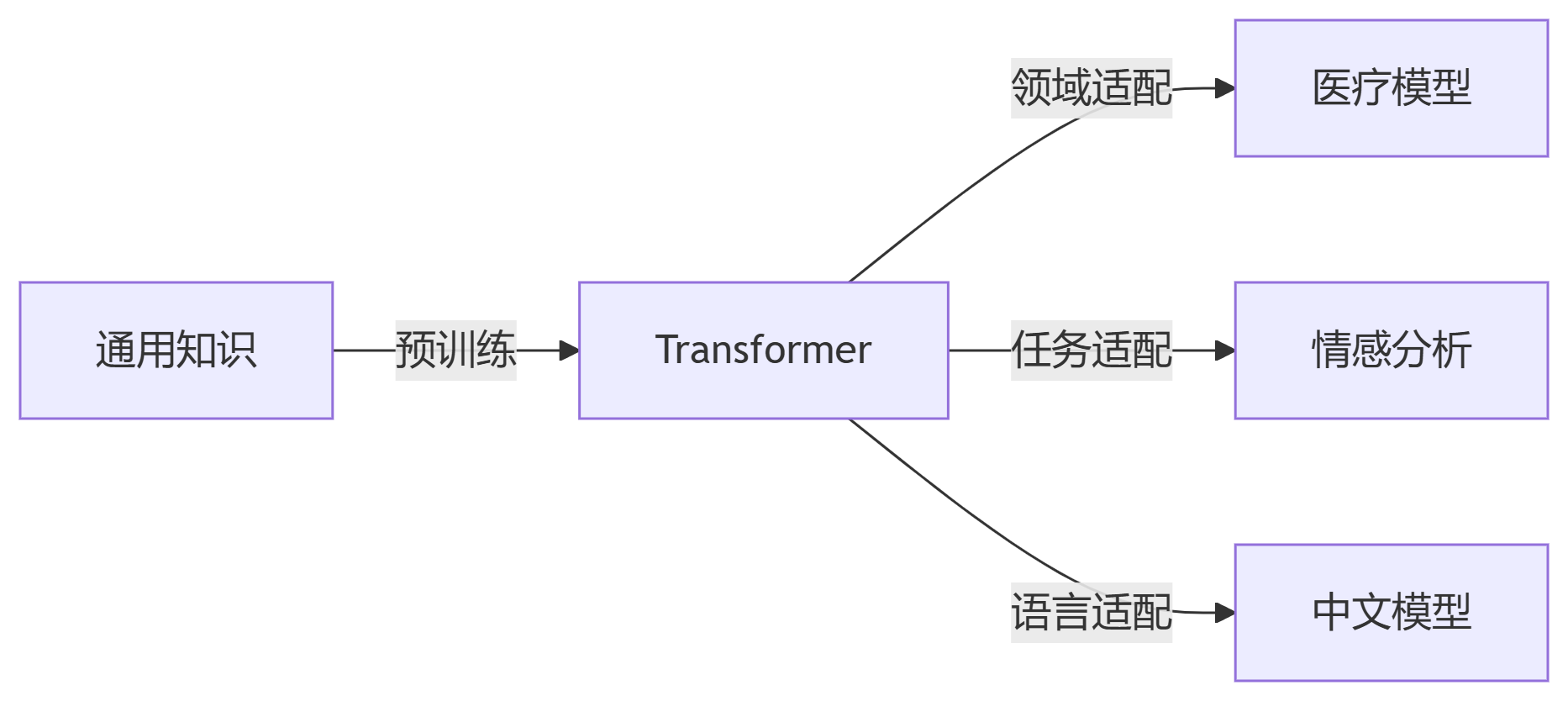
医疗诊断报告分类
领域差异大 → 必须微调
方法:先领域预训练,再任务微调
多语言情感分析
语言差异 → 适配器微调
共享主干,语言特定适配器
法律条款解析
专业术语 → 提示微调 + 知识注入
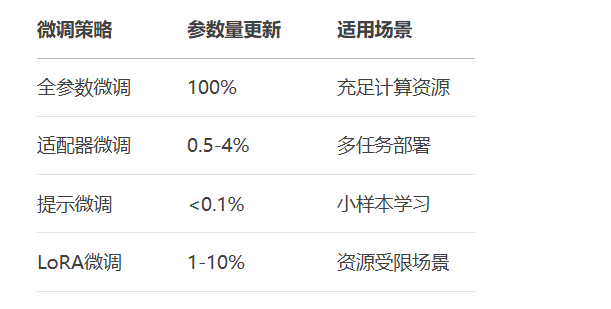
from peft import LoraConfig, get_peft_model
# 配置LoRA
lora_config = LoraConfig(
r=8, # 秩
lora_alpha=32,
target_modules=["query", "value"], # 作用模块
lora_dropout=0.05,
bias="none"
)
# 应用LoRA
model = AutoModelForSequenceClassification.from_pretrained("bert-base")
peft_model = get_peft_model(model, lora_config)
# 仅训练0.1%参数
peft_model.print_trainable_parameters()
# trainable params: 1,048,576 || all params: 134,000,000 || 0.78%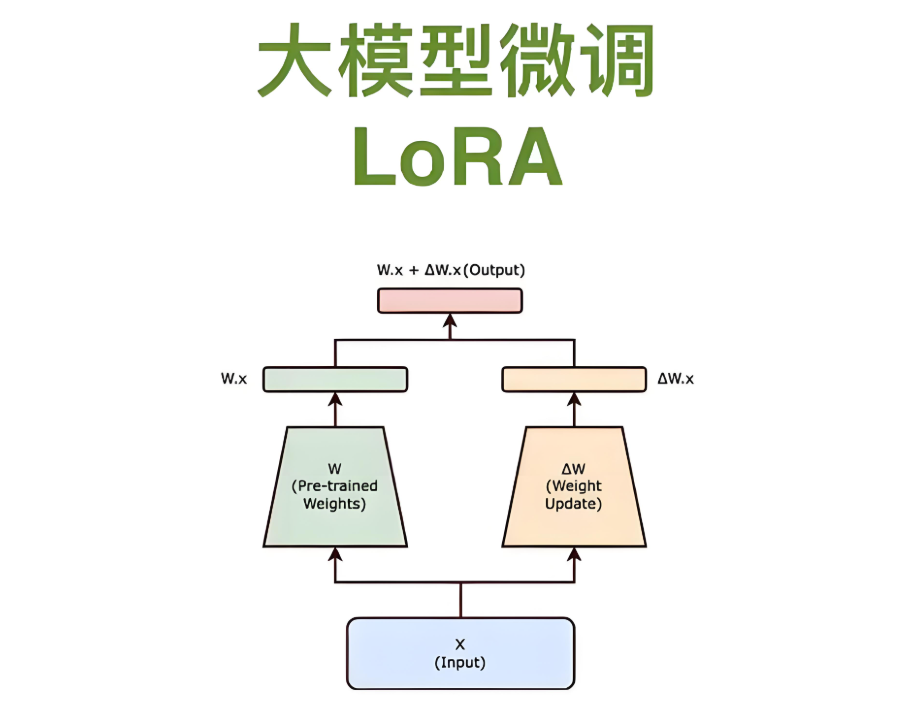
from transformers.adapters import AdapterConfig
# 添加适配器
config = AdapterConfig(mh_adapter=True, output_adapter=True)
model.add_adapter("medical", config=config)
model.train_adapter("medical") # 冻结主干,仅训练适配器
# 激活适配器
model.set_active_adapters("medical")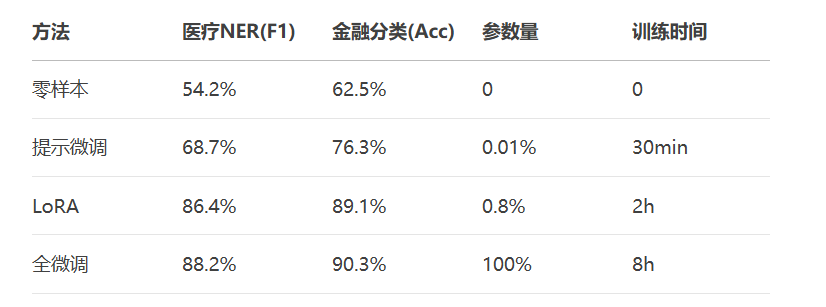
# 分层学习率设置
optimizer = AdamW([
{'params': model.base_model.parameters(), 'lr': 3e-5},
{'params': model.classifier.parameters(), 'lr': 1e-4}
])from transformers import EarlyStoppingCallback trainer.add_callback(EarlyStoppingCallback(early_stopping_patience=2))
权重衰减
training_args = TrainingArguments(weight_decay=0.01) # 防止过拟合
梯度裁剪
training_args = TrainingArguments(max_grad_norm=1.0) # 稳定训练
场景1:小数据集过拟合
方案:冻结底层+仅微调顶层
for param in model.base_model.parameters(): param.requires_grad = False
场景2:领域漂移问题
方案:渐进解冻策略
# 分阶段解冻层 unfreeze_layers = [8, 9, 10, 11] # 最后4层 for layer in unfreeze_layers: for param in model.encoder.layer[layer].parameters(): param.requires_grad = True
场景3:多任务冲突
方案:适配器共享
model.add_adapter("task1")
model.add_adapter("task2")
model.active_adapters = Stack("task1", "task2") # 共享表示终极建议:80%场景下,LoRA微调是最佳性价比选择!更多AI大模型应用开发学习视频内容和资料,尽在聚客AI学院。



