LlamaIndex 是一个专为大语言模型(LLM)设计的开源数据框架,核心目标是构建高效的检索增强生成(RAG)系统。它通过结构化数据索引和智能检索机制,帮助开发者将私有数据与LLM结合,解决大模型知识时效性不足和领域适应性差的问题。
应用场景:
企业知识库问答系统
法律/医疗文档智能分析
多源数据聚合检索
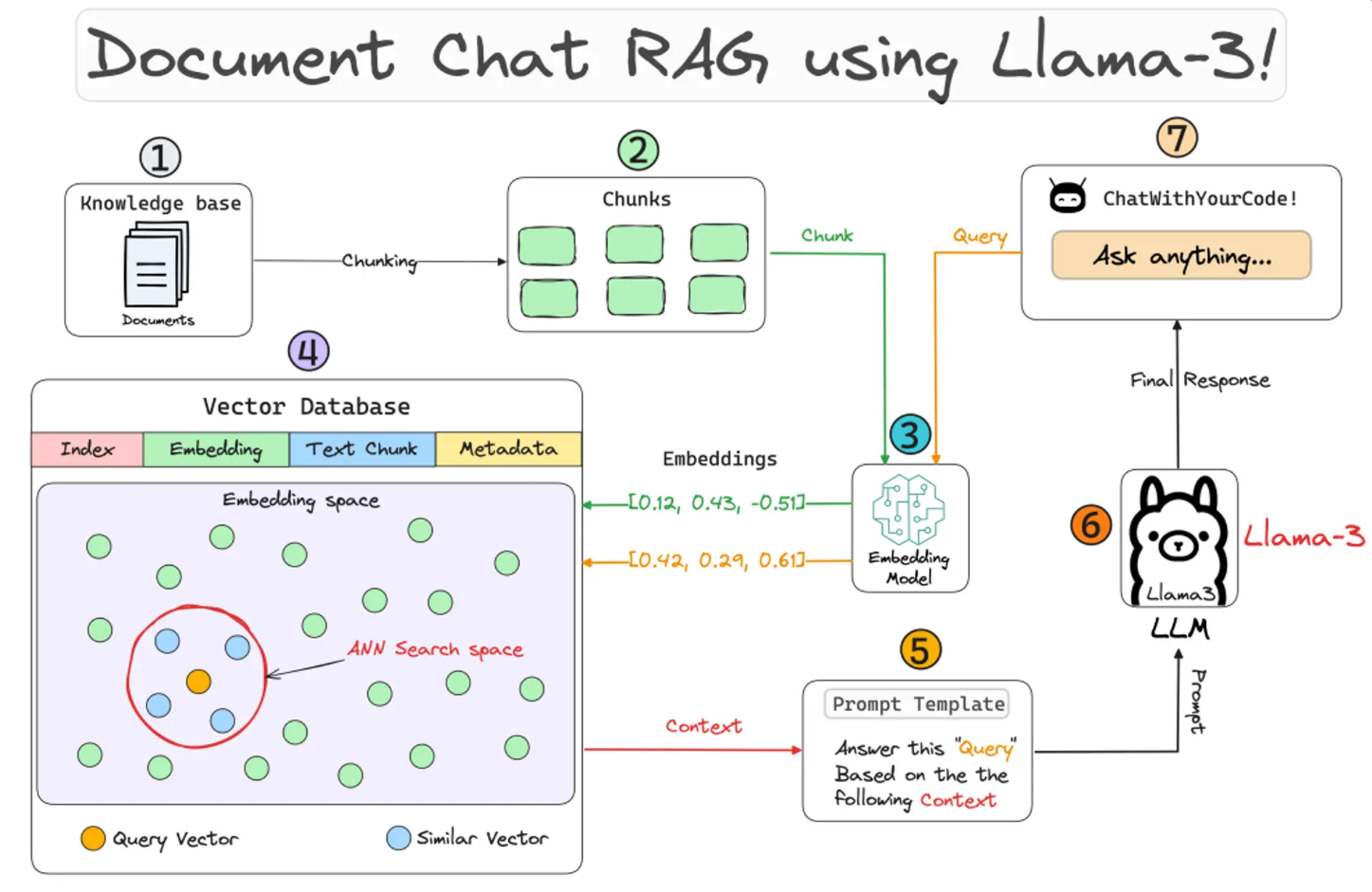
数据整合:支持PDF、Markdown、SQL数据库等20+格式数据统一处理
高效检索:通过向量索引、关键词索引等多策略快速定位信息
上下文增强:为LLM提供精准的参考文档片段,提升生成质量

数据源 → 数据连接器 → 文档 → 节点 → 索引 → 查询引擎 → 响应生成
核心模块:
索引阶段:数据加载、分块、向量化
查询阶段:检索优化、结果合成
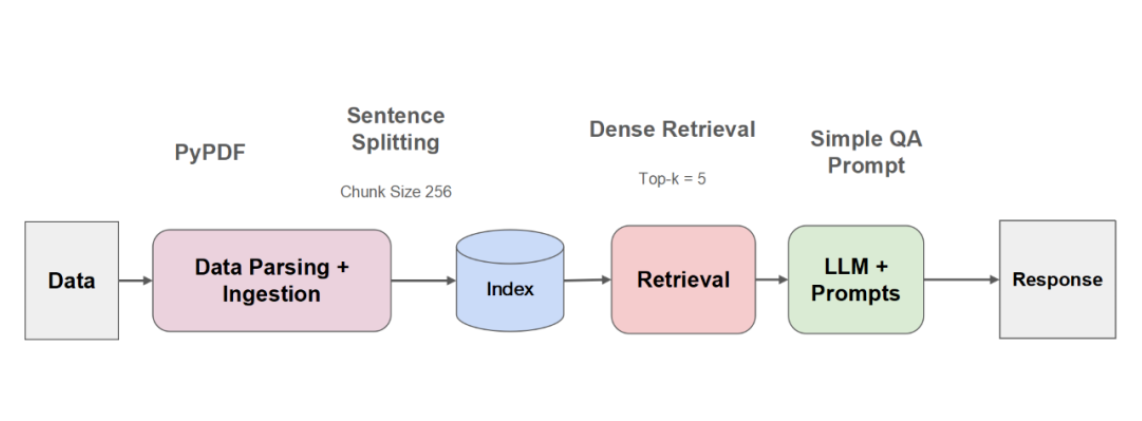
支持从本地文件、数据库、APIs等获取数据:
代码示例:加载PDF文件
from llama_index.core import SimpleDirectoryReader
# 加载目录下所有PDF
reader = SimpleDirectoryReader(input_dir="data", file_extractor={".pdf": "PDFReader"})
documents = reader.load_data()
print(f"已加载 {len(documents)} 篇文档")Document:原始数据单元(如单篇PDF)
Node:文档分块后的最小处理单元,包含元数据和嵌入向量
分块策略代码示例:
from llama_index.core.node_parser import SentenceSplitter # 按句子分块,块大小512字符 parser = SentenceSplitter(chunk_size=512) nodes = parser.get_nodes_from_documents(documents)
索引类型:
向量索引:基于嵌入向量的语义搜索
关键词索引:倒排索引快速匹配
摘要索引:提取核心内容加速检索
代码示例:创建向量索引
from llama_index.core import VectorStoreIndex # 自动生成嵌入并存储 index = VectorStoreIndex(nodes) index.storage_context.persist(persist_dir="./storage")
执行检索并返回结果的核心接口:
代码示例:基础查询
query_engine = index.as_query_engine()
response = query_engine.query("什么是机器学习?")
print(response)5.2 聊天引擎(Chat Engine)
支持多轮对话的上下文管理:
代码示例:对话历史保持
chat_engine = index.as_chat_engine()
response = chat_engine.chat("深度学习的优势是什么?")
print(response) # 首次回答
response = chat_engine.chat("它与传统机器学习有何不同?") # 继承上下文5.3 代理(Agents)
智能路由选择工具:
代码示例:多工具代理
from llama_index.core.tools import QueryEngineTool
# 定义两个查询引擎
tool1 = QueryEngineTool.from_defaults(query_engine=engine1, name="技术文档")
tool2 = QueryEngineTool.from_defaults(query_engine=engine2, name="产品手册")
# 创建代理
agent = OpenAIAgent.from_tools([tool1, tool2])
response = agent.chat("请对比A产品和B产品的技术规格")检索策略:
VectorIndexRetriever:向量相似度检索
KeywordTableRetriever:关键词匹配
HybridRetriever:混合策略
代码示例:混合检索
from llama_index.core.retrievers import VectorIndexRetriever, KeywordTableRetriever vector_retriever = VectorIndexRetriever(index=index, similarity_top_k=2) keyword_retriever = KeywordTableRetriever(index=index, keyword_tables=keyword_table) # 合并结果 retrieved_nodes = vector_retriever.retrieve(query) + keyword_retriever.retrieve(query)
5.5 节点后处理器(Node Postprocessors)
优化检索结果:
SimilarityPostprocessor:按相似度阈值过滤
KeywordFilter:基于关键词筛选
代码示例:结果过滤
from llama_index.core.postprocessor import SimilarityPostprocessor postprocessor = SimilarityPostprocessor(similarity_cutoff=0.7) filtered_nodes = postprocessor.postprocess_nodes(retrieved_nodes)
生成最终自然语言响应:
代码示例:流式生成
from llama_index.core import get_response_synthesizer synthesizer = get_response_synthesizer(streaming=True) streaming_response = synthesizer.synthesize(query, nodes=filtered_nodes) for text in streaming_response.response_gen: print(text, end="")
分块策略:根据文本类型调整chunk_size(技术文档建议512-1024字符)
索引选择:高查询频率场景使用内存索引,大数据量使用磁盘索引
缓存机制:对常用查询结果进行缓存(如使用Redis)
代码示例:缓存配置
from llama_index.core import Settings from llama_index.cache import RedisCache Settings.cache = RedisCache(host="localhost", port=6379)
注:本文代码基于LlamaIndex 0.10+版本实现,更多AI大模型应用开发学习内容,尽在聚客AI学院。



