核心公式:
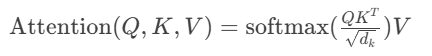
物理意义:通过计算词向量间的相关性权重,动态捕捉远距离依赖。相比CNN/RNN,突破了局部感受野限制。
主流方案对比:

旋转位置编码(RoPE)示例:
# 简化版RoPE实现 def apply_rope(q, k, pos_ids): angle = 1.0 / (10000 ** (torch.arange(0, d_model, 2) / d_model)) sin = torch.sin(pos_ids * angle) cos = torch.cos(pos_ids * angle) q_rot = q * cos + rotate_half(q) * sin k_rot = k * cos + rotate_half(k) * sin return q_rot, k_rot
数据并行:将批量数据拆分到多个GPU
流水线并行:按模型层拆分到不同设备
LoRA微调代码实战:
from peft import LoraConfig, get_peft_model config = LoraConfig( r=8, lora_alpha=32, target_modules=["query", "value"], lora_dropout=0.1 ) model = get_peft_model(base_model, config) # 仅训练适配器参数 optimizer = AdamW(model.parameters(), lr=3e-4)
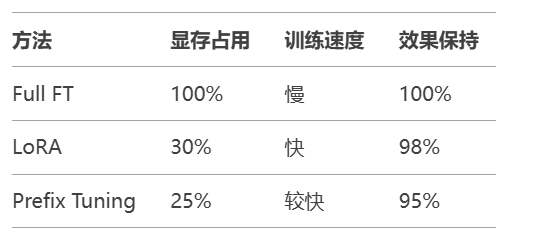
微调策略对比:
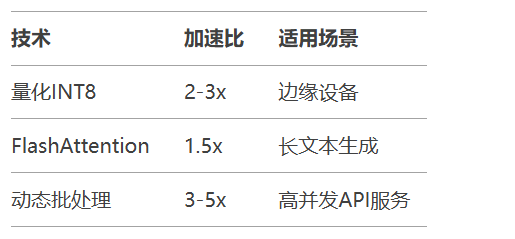
典型优化组合:
# ONNX Runtime部署示例
from transformers import AutoModelForCausalLM
import onnxruntime as ort
model = AutoModelForCausalLM.from_pretrained("Llama-2-7b")
model.export_onnx("llama2.onnx")
sess = ort.InferenceSession(
"llama2.onnx",
providers=['CUDAExecutionProvider']
)优化技术矩阵:
微服务化部署方案:
graph TD
A[客户端] --> B{API网关}
B --> C[负载均衡]
C --> D[模型实例1]
C --> E[模型实例2]
C --> F[模型实例N]
D --> G[GPU集群]核心组件:
流量控制:令牌桶限流算法
健康检查:心跳监测+自动恢复
灰度发布:AB测试模型版本
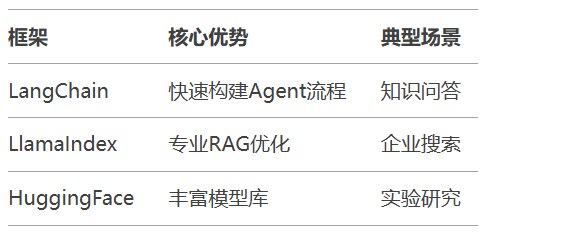
文档问答系统搭建:
from llama_index import VectorStoreIndex, ServiceContext
from langchain.embeddings import HuggingFaceEmbedding
embed_model = HuggingFaceEmbedding("BAAI/bge-base-zh")
service_context = ServiceContext.from_defaults(embed_model=embed_model)
index = VectorStoreIndex.from_documents(
documents,
service_context=service_context
)
query_engine = index.as_query_engine(similarity_top_k=3)
response = query_engine.query("如何申请年度休假?")架构特性:
动态路由选择专家模块
相同参数量下训练速度提升5倍

将注意力矩阵映射到量子态空间
理论复杂度从O(n²)降为O(n log n)
融合方案:
# 符号规则与神经网络协同推理 if check_symbolic_rules(input): return apply_rule_based_solution(input) else: return llm.generate(input)
掌握核心技术栈需要理论理解与工程实践并重。建议从单点技术突破(如LoRA微调),逐步扩展到完整系统构建,最终实现商业场景的技术闭环。



